Summoned by the Question
What mechanistic interpretability says about whether an LLM commits to a secret in 20 Questions.

Have you ever played 20 questions as the questioner with an LLM and wondered, is it actually holding a concept in its latent state or just improvising and, at the end, revealing a plausible animal given its previous yes/no answers? This is the question I endeavored to answer using mechanistic interpretability techniques to read into what the model is ‘thinking’ during the game.
Tl;dr
I used a set of 20 animals, described the game to Gemma-3-12B-it and Gemma-3-27B-it, instructing them to say “Ready” once they have made their pick from the set. I ask only 4 questions for efficiency, and lastly ask them to reveal the animal.
- Models only choose a subset of animals even across multiple trials, 12B: just 4 animals, and 27B: 7 animals.
- 12B shows signs of pure improvisation: probing signals are at chance-level (1.2x) by the time the model says “Ready”, and only get clearer as we get closer to reveal.
- 27B’s results confirm that decodability ≠ causality: the linear probe picks up on what animal the model will reveal already at “Ready” (3.55x above chance); however, this readability does not pass causal intervention tests with patching and steering. Probe steering shows it becomes causal only gradually, after the first question.
Motivation
Recent research intriguingly showcases evidence that LLMs have more internal knowledge than they actually output, can hold ulterior motives without expressing them, and are capable of latent introspection (Gekhman et al. 2025; Anthropic 2026; Pearson-Vogel et al. 2026). While playing a game of 20 questions with ChatGPT, I wondered “does it actually have a concept in mind or is it just making it up on the way?”. One way to easily test this directly in the chat is to regenerate the responses multiple times, branching, and going back to see if final answers changed. This is obviously subject to randomness though, because of the likely non-zero temperature and infrastructure quirks.
This brought me to the idea of utilizing mech interp to peer into the model’s internal representations while playing the game. I looked for existing studies investigating this and only found one (Luo et al. 2026). They tested for consistency in LLMs in a 20-questions-style game, but they only did so using closed source LLMs, and thus were limited to scratchpad-like environments to simulate latent reasoning, and not neural activations. In this setting, they found that LLMs struggle to maintain consistency. I’m testing whether LLMs can commit to a latent idea without first putting it into text.
Set-up
The models
Gemma-3-12B-it and Gemma-3-27B-it, selected because of their well documented mech interp resources (Gemma Scope 2 and Neuronpedia).
The animals
Candidate list of animals chosen for attribute diversity (every pair differs on ≥2 attributes) across taxonomy, habitat, diet, size, domesticity, geography:
[tiger, elephant, kangaroo, bat, dolphin, gorilla, cow, dog, cat, horse, eagle, penguin, chicken, owl, cobra, crocodile, frog, shark, salmon, bee]
What the model actually chooses (n=600)
Despite 20 options, the realized distribution collapses onto a handful (cow, dog, elephant, horse for 12B). For 27B:
| Animal | n |
|---|---|
| Horse | 240 |
| Tiger | 201 |
| Cow | 53 |
| Elephant | 49 |
| Dog | 32 |
| Gorilla | 23 |
| Shark | 2 |
7 realized classes; horse + tiger = 73%. shark (n=2) is degenerate and gets dropped from balanced analyses. I even tried increasing/balancing the realized class distribution by running with temperature = 0.7, but it barely changed anything.
The game description
I describe the game in a system prompt (“you’re playing 20 questions, an adversary will ask yes/no questions about a secret animal, answer truthfully, and never reveal it”), then hand over the candidate list and ask the model to commit:
“Choose exactly one animal from the list above and commit to it as your secret for the entire game. Keep the choice fixed; do not change it. Do not state the name of the animal. When your choice is locked in, reply with only the single word: Ready”
That single word “Ready” is the whole ballgame for me. It’s the first moment the model claims to have committed, but it hasn’t yet emitted anything that reveals what it committed to, so the residual stream at that position is the cleanest possible place to ask “is there an animal in there?”. After “Ready”, the game proceeds through the questions and then the reveal.
All games run with greedy decoding (the model always takes its highest-probability token).
The questions
I ask 4 yes/no questions per game, drawn from a panel of 30 binary predicates (is it a mammal?, is it larger than a human?, is it a carnivore?, does it have stripes?, is it domesticated?, and so on). Four questions is enough to watch the model’s internal state evolve turn by turn, but short enough to run hundreds of games cheaply. Each turn is just:
“{question} Reply with only one word: Yes or No”
Then the reveal:
“The game is now over. Please reveal the single animal you had been using as your secret. Reply with only the name of that animal.”
Whatever the model says at the reveal is the ground truth I decode against. It’s the label I ask the probes to predict from earlier activations.
Worth noting up front: these four questions don’t actually distinguish the animals the model picks. Almost every game produces the same transcript, Yes / No / No / Yes (only shark, n=2, differs), because the realized set collapsed onto near-identical four-legged mammals. So the dialogue carries essentially no information about which animal it is, a fact that matters a lot later.
Calibration
Before trusting any of this, I ran an assigned condition where I tell the model exactly which animal to hold (referenced by its position in the shuffled list). Since I know the answer, it’s a sanity check that my probes actually fire when there’s genuinely a concept to read. They do: a linear probe recovers the assigned animal near-perfectly at “Ready” (around 100% accuracy by the middle layers, against a 25% chance baseline). With the pipeline calibrated, everything that follows uses the self-chosen condition, where the model picks for itself and nobody, including me, knows the choice until the reveal.
Reading the internals
To peek inside, I capture the residual stream at a set of structural anchor positions along the game’s chat, most importantly the end of “Ready”, the end of each question turn, and the moment just before the reveal, across every layer (49 for 12B, 63 for 27B). At each (position, layer) I fit a leave-one-out linear probe to predict the eventually-revealed animal, which tells me how decodable the choice is and when it becomes legible. But decodability isn’t the same as the model actually using that information, so I also run activation patching and steering to test whether those directions are causally load-bearing, plus sparse autoencoders (Gemma Scope 2, labeled via Neuronpedia) to ask whether the decodable signal lives in clean, interpretable features or is just smeared across the residual. That gap between decodability and causality turns out to be the heart of the story.
When I patch or steer, there are two ways to run the rest of the game. The default is teacher-forced: I hold the transcript fixed (the same four questions and the model’s original Yes/No answers) and only let the reveal regenerate. This asks one clean question: holding the public conversation constant, do the patched residuals determine the committed animal? The catch is that a teacher-forced model might just stay coherent with the frozen answers and reveal accordingly, which would hide whether the residual really carried the commitment. So I also run answer-rollout: after the intervention I let the model regenerate its own Yes/No answers too, giving it the chance to change them. If the intervention truly rewrote the internal choice, both the answers and the reveal should follow, though only on the subset of questions that actually distinguish the animals.
Results
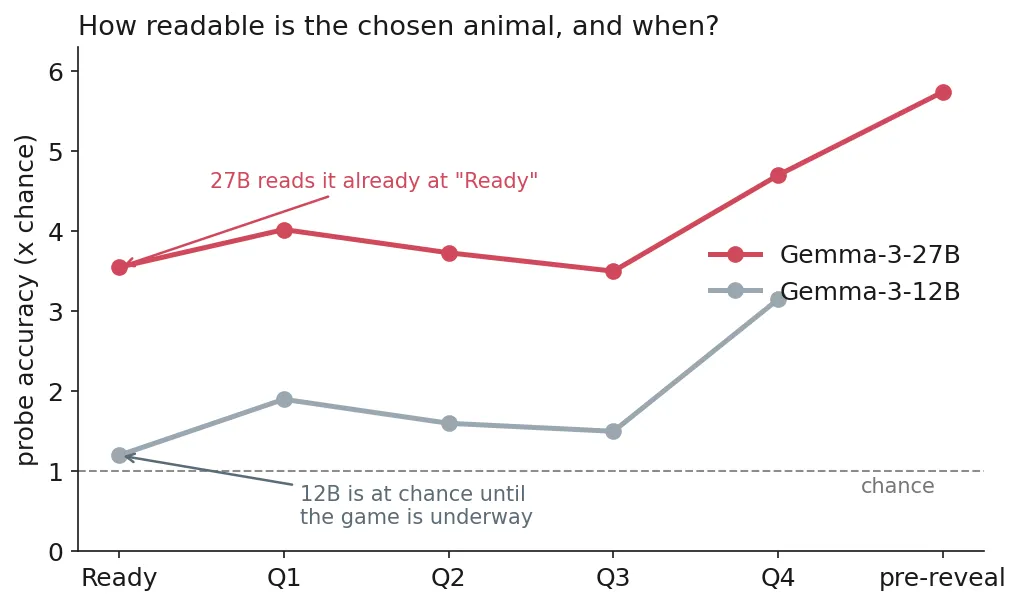
12B improvises; 27B looks like it decides early
12B is at chance the moment it says “Ready” (1.2× chance) and only firms up as the questions constrain it, peaking around 3× chance by the fourth question. 27B reads the eventual animal already at “Ready,” 3.55× chance (50.8% across 7 animals), and stays well above chance through to the reveal (~5.7× just before). At face value the bigger model decides up front. The next three results say it doesn’t.
Patching the “Ready” state transfers nothing
Take the residual stream from a tiger game, patch it into a horse game (activation patching), run it out, watch the reveal. I started teacher-forced across several variants (single position, layer bands, all layers at once, multiple positions) and it was null. The stronger answer-rollout test, which lets the model rewrite its answers, was null too:
| protocol (27B, end_ready) | kept original | flipped to source |
|---|---|---|
| teacher-forced (bands → full-residual L1–62) | ~98% | 0 off-diagonal1 |
| answer-rollout, L14–18 | 98.3% (1007/1024) | 0.2% (2/870) |
Steering is causal later, not at “Ready”
Add the difference-of-means direction between two animals (contrastive activation addition, CAA) into the residual and see if the reveal follows. Same intervention, six positions. At “Ready” it does almost nothing (1% flip), and there’s a mechanical reason: the between-animal direction there has a norm of about 52, versus ~760 at Q1 and ~1570 by Q4. There’s barely anything to push on. The choice becomes steerable only once the dialogue is underway: ~35% flip after Q1, ~70% by Q4.
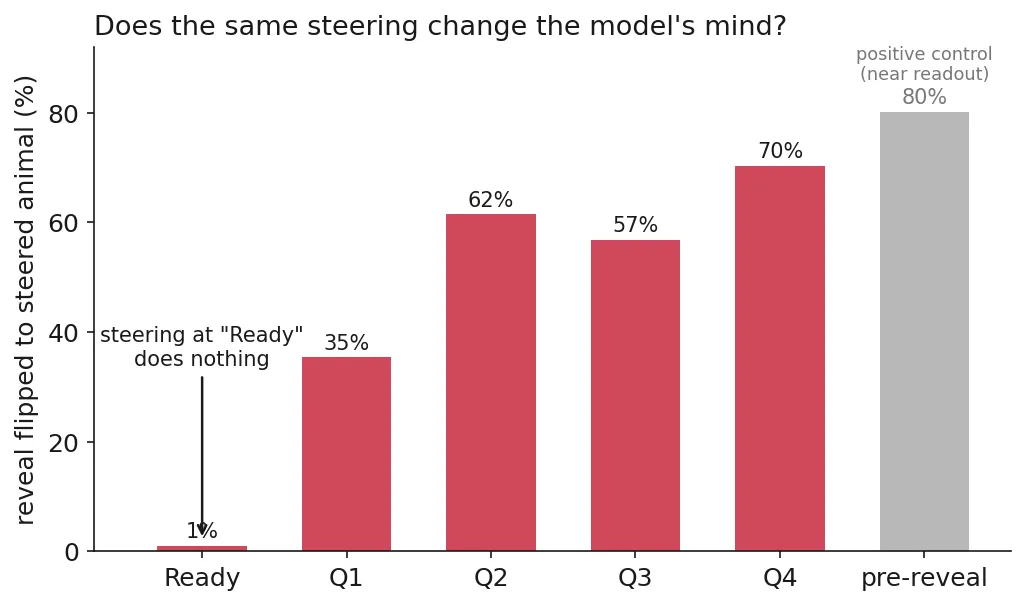
And even where the reveal does flip, the model mostly keeps playing the original game. On the diagnostic questions for a given pair (the ~22% of questions whose truthful Yes/No actually differs between the original animal and the one I’m steering toward), the steered run’s answers stay 65–85% in line with what the original animal would truthfully answer, and the raw rate of changed answers is near zero. At Q2, for instance, the reveal flips to the steered animal 61.5% of the time, yet 0 of 768 answer slots change relative to the unsteered run, and those answers still match the original animal’s truthful Yes/No 72.8% of the time. The 72.8% is not a sign that steering nudged the answers: it’s identical with and without steering (nothing moved), and it sits below 100% only because the model isn’t perfectly truthful to its own pick even in the unsteered game. So steering moves the final reveal word more than it rewrites the game the model is actually playing, which is the opposite of what you’d see if it were flipping a single stored commitment.
The “Ready” signal isn’t a clean feature
There’s one last sense in which the “Ready” signal might be a real, used representation: maybe it’s a clean, interpretable feature, the kind a sparse autoencoder would isolate as “the model is thinking of a horse.” So I ran the 27B “Ready” activations through Gemma Scope 2’s SAE (near-perfect reconstruction, FVU 0.005, where FVU is the fraction of variance unexplained) and asked two things: does the class signal survive in the sparse code, and what do the active features actually mean?
The sparse code keeps only about half the class information the dense residual carries (1.80× vs 3.05× chance, on the matched 6-class setting with shark dropped, which is why the dense baseline here is 3.05× rather than the 3.55× quoted earlier for 7 classes). And only 45 of 65,536 features fire at all, every one class-invariant, with Neuronpedia labels that are pure formatting: “names of people,” “XML tags and identifiers,” “HTML tags and URLs,” “code files and definitions.” Not one animal, size, or attribute feature. The interpretable content at “Ready” is the chat template the model is sitting in, not the animal it supposedly picked.
But the same SAE tells the rest of the story the moment I move one position later. At the first question (same layer, so this is the question’s effect, not the layer’s), the loud features stop being formatting and become two things at once: yes/no-answering features (“question followed by yes/no/maybe,” “true/false values”), and animal-taxonomy features that were absent at “Ready,” including ones Neuronpedia labels “mammals” and “animal classification and biology.” Keep going and the features track each question’s literal content: the four legs question lights up “how it walks,” “anatomical parts,” and “dimensions and scales,” while the two questions the model answers “No” to (bird?, water?) are dominated by negation features (Fig 3).
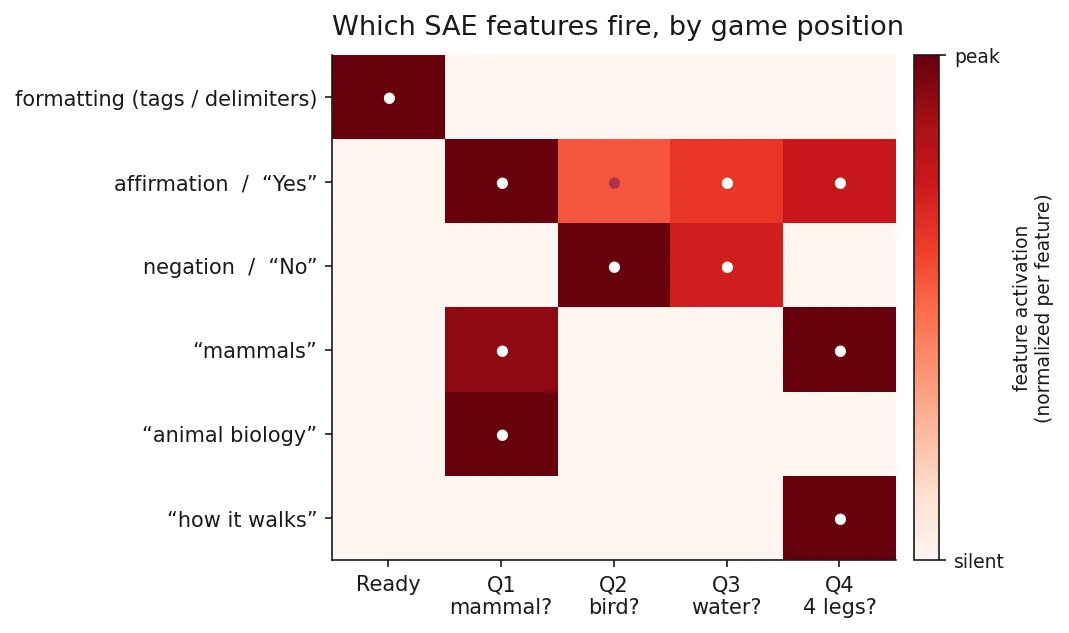
The animal space comes online exactly when a question forces the model to consult it. That’s the whole point in one figure: at “Ready” there is no animal in the features, only the shape of the chat; the choice is summoned by the question, not retrieved from storage.
What I make of this
Three independent senses of “is the choice really in there at Ready,” all negative for 27B’s early signal: you can’t transplant it (patching), you can’t push on it (steering), and it isn’t a clean feature (SAE). The one thing it is is linearly readable, which turns out to be the weakest kind of evidence.
So the early “decision” is better read as the model re-deriving its choice from the prompt at every step rather than storing and defending it. This fits how we run the game: with greedy decoding the chosen animal is a deterministic function of the prompt, and the only thing varying across games is the order of the listed candidates. It isn’t coming from the dialogue either, since the animals the model picks answer the four questions almost identically (Yes/No/No/Yes), so the transcript barely distinguishes a horse-game from a tiger-game. The choice can only come from the prompt itself. What separates a horse-game from a tiger-game lives only in the residual, recomputed from the permuted prompt on each pass, which is exactly why a direction that summarizes that recomputation is readable but not a lever you can pull on its own.
That also explains the sharp turn-on at the first question. The between-class direction is almost absent at “Ready” (norm ~5) and explodes once a question lands (~760 by Q1, ~1570 by Q4), tracking the steering flip-rates from 1% to 70%. I read the first question as the trigger that makes the model engage the animal space at all. A probe predicting which animal the model will eventually name is not the same as the model holding that animal in mind, and the gap between those two is exactly the thing this post is about. “Ready” is a contentless instruction, so the model has little reason to spend compute settling on which animal it will name. A concrete yes/no question forces it to consult an animal’s actual properties to answer, which is why the “mammals” feature fires at the mammal question and “how it walks” at the four-legs question (Fig 3). That is what moves the residual into a region where the classes are both linearly separated and causally live. The question summons the choice into a usable form, which is exactly the on-demand, question-driven computation an instruction-tuned model is built around.
So why is the 12B model unreadable at “Ready” if it improvises the same way? My best guess is that decodability there isn’t measuring whether the model has committed, but how linearly correlated the eventual reveal already is with the residual at that position, and that scale increases that correlation. The 27B leaves a readable shadow of its eventual pick at “Ready” (chance → 3.55×) where the 12B leaves none until the questions force the computation. But I want to be careful not to oversell this shadow: there is no animal feature in the SAE at “Ready,” and steering there does nothing, so whatever the probe is reading is faint and inert, not a worked-out representation of the animal. The safest reading is that scale buys earlier legibility of where the model is heading, not an earlier commitment. Decodability scaled; causality didn’t.
Two honest limitations. First, my causal claims rest on null results, and a null is absence of evidence: patching and a coarse difference-of-means steer are blunt instruments, so a more expressive intervention could surface causal structure I’m missing (though it would have to do so where three different methods found nothing). Second, this is a narrow slice, two models in one family, a single prompt style, and a realized class set that collapses to seven mammal-heavy animals, so I can’t yet separate “improvisation is how these models play 20 questions” from “improvisation is how models in general do.”
Conclusion and future work
Playing 20 questions against Gemma-3, the answer to “is it holding a concept or making it up as it goes?” is mostly making it up, even for the model that looks like it isn’t. The choice is improvised and assembled from the dialogue, not committed at “Ready” and protected. Scale makes the improvisation more legible to a probe without making it any more real to the model.
Where I’d take this next:
- Push the scale axis. The most interesting open question is whether “early decision vs. late crystallization” flips in a much larger model. I’d genuinely hope to find a model that does commit early; that would be the real test of whether improvisation is fundamental or just a small-model habit.
- Other model families and more prompts. Everything here is Gemma-3 with one prompt style. Running the same protocol across families (and with varied phrasings and question panels) would show whether this is a property of these models or of the task.
- Mediation, not just intervention. Causal Mediation Analysis (CMA) to quantify how much of the reveal each position actually accounts for, rather than the binary flip-rate.
- Sharper SAEs. A wider SAE (262k) or transcoders, to check the “no class feature” result isn’t a width artifact.
The code, data, and figures behind this post are on GitHub: TimeTravelerTy/twenty_questions_interp.
References
- Gekhman, Z., Ben David, E., Orgad, H., Ofek, E., Belinkov, Y., Szpektor, I., Herzig, J., and Reichart, R. (2025). Inside-Out: Hidden Factual Knowledge in LLMs. arXiv:2503.15299.
- Anthropic (2026). Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations. Transformer Circuits, May 2026. transformer-circuits.pub/2026/nla.
- Pearson-Vogel, T., Vanek, M., Douglas, R., and Kulveit, J. (2026). Latent Introspection: Models Can Detect Prior Concept Injections. arXiv:2602.20031.
- Luo, Y., Xu, K., Lu, Y., Yuan, Y., and Yao, A. C.-C. (2026). Probing the Lack of Stable Internal Beliefs in LLMs. arXiv:2603.25187.
Appendix A: decodable but not steerable
It can feel paradoxical that the eventual animal is linearly decodable at “Ready” (~3.5× chance) while the between-animal direction there has a norm of only ~5, far too small to steer with. The resolution is that decodability and steerability measure different things, and they come apart for a faint-but-clean signal.
A linear probe separates classes by the gap between class means relative to the within-class spread (a signal-to-noise ratio, ), and it rescales that direction freely, so absolute magnitude is irrelevant. Steering does the opposite: it adds back into the activations, so its effect scales with the direction’s magnitude relative to the ambient residual ().
Measuring both across the realized animals (6 classes, averaged over pairs):
| position | ‖x‖ | raw ‖μₐ−μᵦ‖ | leverage (raw/‖x‖) | d′ (SNR) |
|---|---|---|---|---|
| Ready (L16) | 3,400 | 5 | 0.0016 | 0.93 |
| Q1 (L38) | 48,600 | 760 | 0.016 | 1.37 |
| Q4 (L38) | 49,200 | 1,570 | 0.032 | 2.49 |
The raw between-class norm spans ~300×, but the scale-free , the part the probe reads, spans only ~2.7×. Most of that raw gap is mundane: activations are ~14× larger at the deeper layer the question anchors peak at. What remains is that the class direction is a genuinely smaller slice of the residual at “Ready” (its steering leverage is ~10–20× lower than at the questions). So the “Ready” signal is readable (its is comparable) but not pushable (its leverage is tiny), which is exactly the regime where a faint, low-variance direction is highly decodable and barely steerable.
Footnotes
-
One game (
attempt_593) is excluded: its reveal sits exactly on the horse/cow decision boundary and tips ~50/50 between the two under any patch, including a horse→horse self-patch. It’s a knife-edge degenerate case carrying no class signal, not a transfer. ↩ -
Wait, if the between-animal direction is that small at “Ready,” how is the animal decodable there at all? Tiny signals can be very readable yet useless to steer with. See Appendix A. ↩